
dri Verless
data to train Driverless vehicles
Mission
Convert the daily, routine driving of ordinary people in their own cars into a data-gathering process, and then use this data to train AVs.
The Verless system mimics humans who drive well.
It captures a driver’s perception: what the eyes are looking at, and what the ears hear, and correlates this with Actuation: how the hands interact with the steering wheel, and how the foot interacts with the accelerator and brake pedals.
Verless correlates perception with actuation to deduce brain functioning, and implements it into Autonomous Vehicles.
Making Autonomous Vehicles more human-like
To mimic humans, Verless:
- Uses crowdsourced ordinary drivers driving their own cars during their routine lives to obtain data.
- Uses a sensor-kit to record the driver’s perception: what he sees and hears using eyes and ears.
- Uses the same sensor-kit to record the driver’s actuation: the interaction of his hands with the steering wheel, the interaction of his foot with the accelerator/brake pedals.
- Detects unusual road events automatically (without human intervention).
- Extracts signatures of such road events automatically (without human intervention).
- Identifies good drivers from the crowdsourced group, and gives them higher weightage.
Sample Costs @ $200 sensor kit per driver, average 5000 miles per year per driver :
$1 million for 5 million miles of data
$25 million for 1 billion miles of data.
Participants enroll online. Accepted applicants are each given a sensor kit consisting of a spectacle frame, a steering wheel cover, and distance sensors to be mounted on the accelerator and brake pedals. Data is gathered by an app on the participants’ phones, and uploaded to a central server for analysis, followed by event and signature extraction.
Data Variety: non-geofenced, urban, rural, different demographics, different regions/countries, different weather and road conditions, peak/lean hours, holidays…
Event detection & signature acquisition is important, not just object recognition
Verless thinks in terms of events rather than objects. Events account for contextualized objects, and more importantly, the way a contextualized object will behave within a time interval.
Objects have different connotations under different contexts. A large dog walking towards the road is not a dangerous situation if the leash is slack. If the dog is dragging on the leash and its human is straining, there is danger.
Recognizing the dog just as an object without any contextual information over a time period will not allow AVs to be trained for all possible variations of scenarios. Such an approach will also provide false positives. An expert driver with decades of experience will contextualize the object and the situation, and react accordingly. Data extracted from such events will provide signatures necessary to mimic good human drivers.
How does the Verless system gather data from a driver?
Example of a driver sensor kit:
- Visual perception: spectacle frame-mounted eye tracker,
- Aural perception (binaural microphones) on the same frame as above,
- Foot actuation sensor (measures depression of accelerator and brake pedals, and when not depressed, the distance of the foot above these pedals),
- Hands actuation sensor (measures contact area and grip of the hands on the steering wheel).
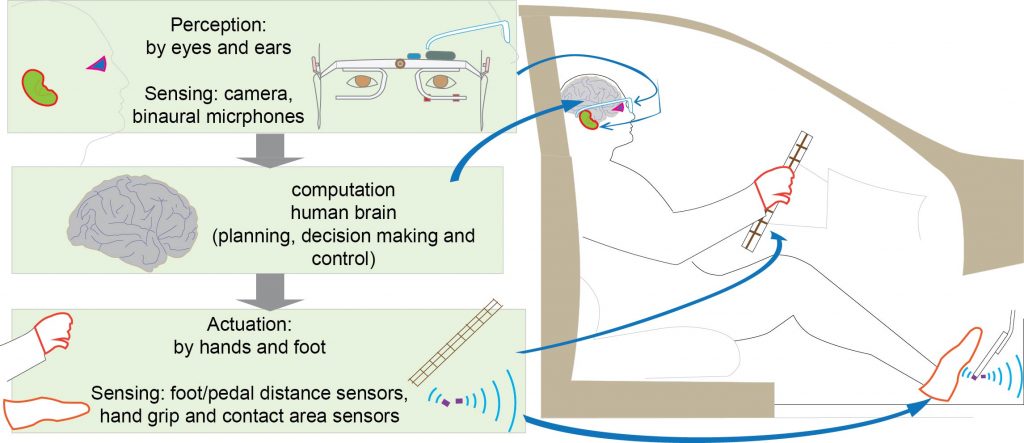
Perception data goes into the brain, which analyzes it and then sends out actuation data to control the steering and the brakes/accelerator. So, we know what’s going into and out of the brain, but can we capture the brain-analysis part in a way that can be directly used in an AV? Yes, Verless does this, and therefore, an AV would react the same way as a human in response to the same visual and aural perception data.
Capturing Visual Perception
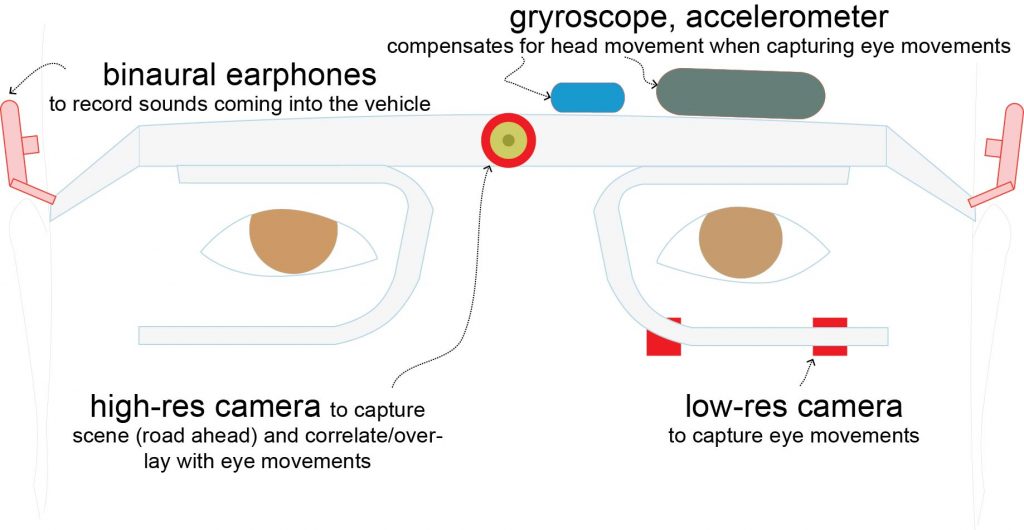
Human eyes move constantly. When driving, eyes scan the scene ahead by moving (called saccades) from one object to another, fix their gaze on some objects (called fixations), dwell on some areas and form regions of interest (ROIs). Eye trackers are used to record eye movements. Eye-tracking can be done using smartphone cameras as well as standalone cameras. For better data acquisition when eye movements are accompanied by head movements, a head-mounted frame is used.
Figure below shows the Verless frame to track eye movement. It includes one or two eye-tracking cameras, a high-res scene camera to capture the road ahead, a gyro and accelerometer to track head movement.
Capturing Aural Perception
In the figure of the eye tracker frame shown above, two aural devices can be seen. These binaural earphones are better than dashboard-mounted microphones.
Hearing in humans does not work like ordinary microphones. The head and nose cast a shadow of sounds, and is further shaped by the geometry and material of the outer and middle ear. Some of this sound is also transmitted through the head. This is mimicked by the frame arrangement (shown above) worn by the driver.
Foot actuation in response to visual and aural perception
The figure below shows sensors placed on the accelerator and brake pedals. These sensors provide the distance between the foot and these pedals.
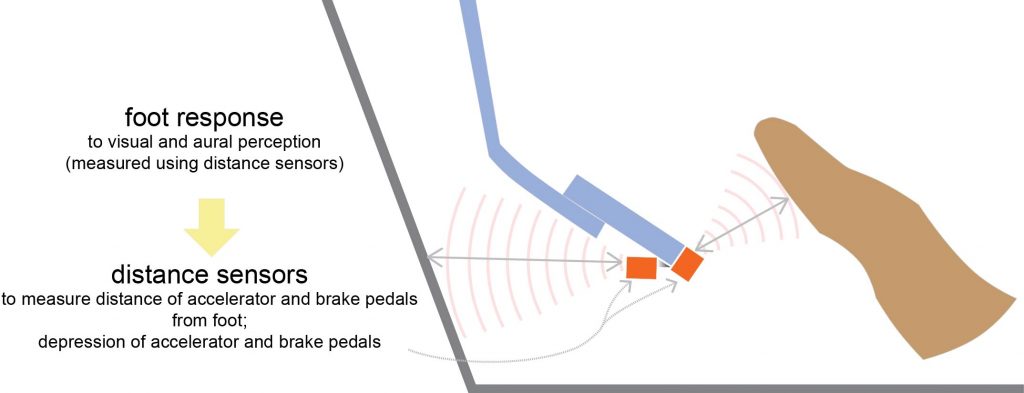
If you are wondering about the purpose of the sensor that measures the distance of the foot from the pedals: when drivers see a potentially dangerous situation, for example, an unaccompanied child at the edge of a road, the foot goes off the accelerator pedal and hovers over the brake pedal.
The distance between the pedal and the foot, or the amount of depression of the pedal, is indicative of the degree of potential harm that must be mitigated. That is, it indicates the driver’s intentions, and is backed by all that the driver has seen and learned in the past decades. This is reflective of the driver’s level of cognition, thinking, judgment, reasoning, insight, risk evaluation, planning, and anticipation. These are components of the driver’s intellect.
The distance or depression is also indicative of the vigilance of the driver in looking out for such situations, the concentration (focussing on important tasks and not being distracted), and attention to the road. These are the indicators of the state of the driver.
This distance or depression is further indicative of the driver’s transaction functioning: memory, speed of association, sensorimotor skills, reaction time and information processing speed.
This information reflects years of driving experience, knowledge gleaned over the years (both in driving as well as everyday life), and the wisdom of the driver.
Hands actuation in response to visual and aural perception
The figure below shows a sensor pad placed on the steering wheel, and having an appearance similar to traditional aftermarket steering wheel covers. These sensors provide the grip force and contact area of the hands on the steering wheel.
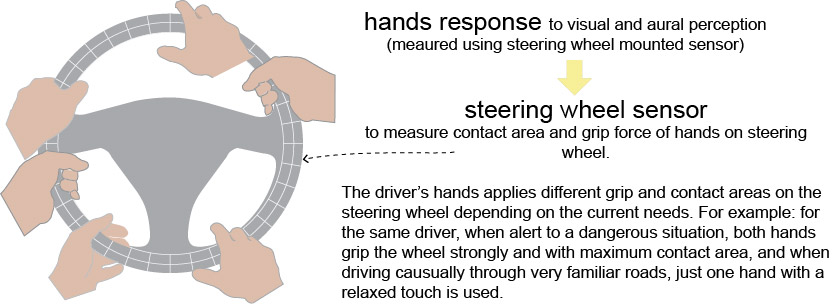
The contact area and grip on the steering wheel for a particular driver varies according to what the driver sees and hears on the road (perception). Similar to the discussion of the distance of the foot from the brake/accelerator pedals as described earlier, the contact area and grip on the steering wheel by the driver is indicative of the driver’s Intellect, State and Transaction components. Again, there is a wealth of information that can be extracted from this data, and is reflective of the driver’s experience, knowledge and wisdom after years of driving.
Implementing visual and aural perception in AVs
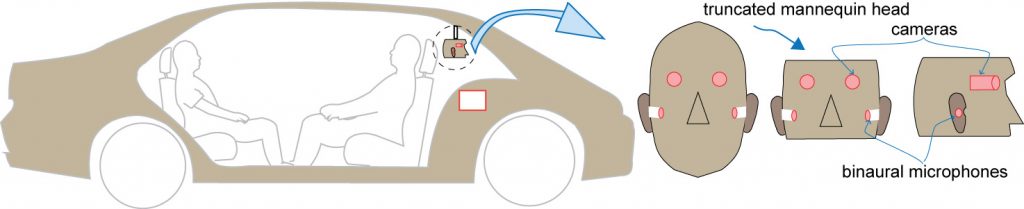
After AVs have been trained with data acquired from expert drivers, the AV’s visual and aural perception is implemented to at least partially match the designs used during data acquisition. A truncated mannequin is used for this purpose as shown below. Although made mostly of polymer, the mannequin head’s density and sound conduction properties are similar to a human head, including the pinnae (outer ear).
so, Camera or Lidar?
Perception in Verless’s method is technology agnostic – Vision and lidar can be combined if necessary, or they can be used individually (that is, just one of them).
The reason for this is simple: we don’t need all information from the road ahead, we need only pertinent information. There is no point in being hyper-alert to every object on the road – it will slow down computation and therefore travel. The question that arises is: what is pertinent information, and who makes that determination? This is left to a crowdsourced group of expert drivers.
The driver’s eyes saccade between objects on the road ahead, forming fixations, dwells and regions of interest around pertinent objects. These eye movements can be one-to-one mapped to images obtained from any one or a combination of cameras, lidars and radars depending on what works best under the current environmental condition.
Problem: Identifying good drivers
We don’t want to base AV training data acquired from bad drivers.
The Verless solution: Scoring drivers on the concept that there are 2 different driving modes:
- Routine driving, when no outside events occur (called non-events driving).
- Driving when unexpected outside events occur.
Not-so-good drivers might drive well under normal non-event conditions, but do not anticipate, recognize and respond to unexpected events like good drivers do. Good drivers do well under non-events as well as events: they drive defensively.
The trick is to score non-events and events separately, scale them if necessary, and then combine them. Then set a threshold score, select drivers from the cohort who are above this threshold (called Expert Drivers), and use the data obtained from their driving as AV training data. The scoring can be localized to a particular geographical region, or specific driving condition (examples: night time drivers, foggy conditions, peak traffic in crowded city center). A large number of drivers in the same region or under the same conditions results in better training data. The more EDs, the better the training data.
The end result of the Verless method:
- Captures decades of driving experience of EDs.
- AVs react like EDs for each specific scenario or unexpected event.
- Does not averaging-out data – excludes poor drivers/bad data.
- Signatures of unexpected events can be classified granularly to narrow variations.
- AVs will behave close to 100% of good human drivers.