
Welcome to WordPress. This is your first post. Edit or delete it, then start writing!
Human-like Autonomous Vehicles
using data gathered by crowdsourced experts driving own cars during normal livesProblem: How to make AVs more human-like?
The solution?
Mimic humans who drive well.
How?
Automatically gather data from thousands of crowd-sourced volunteers driving their own cars during their routine daily driving.
What Data?
Perception and Actuation. What the driver sees and hears, and what he does in response.
What’s required?
Figure below shows a $200 kit per driver, comprising: (a) visual perception: eye tracker, (b) aural perception (binaural microphones), (c) foot actuation sensor (measures depression of accelerator and brake pedals, and when not depressed, the distance of the foot from these pedals), (d) hands actuation sensor (measures contact area and grip of hands on steering wheel). Details of sensing appears later.
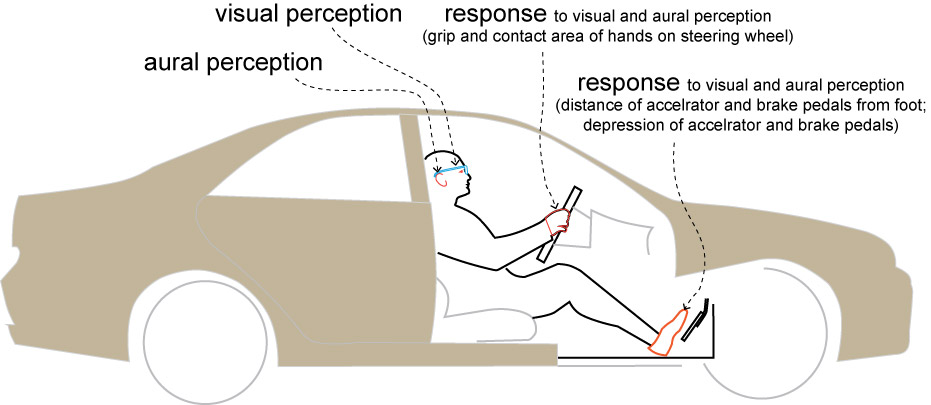
Why mimic human drivers?
After capturing Perception and Actuation data, we can correlate them to events occurring outside the vehicle, and what the driver did in response.
(a) Perception: data related to what drivers see with their eyes and hear with their ears.
(b) Actuation: data related to responses of drivers to Perception: what they do using their feet and hands to control the vehicle. This also captures the driver’s intellect: intentions, cognition, thinking, judgement, reasoning, insight, risk evaluation, planning, anticipation, cognitive inhibition, habituation, sensitization.
Signtaures can then be extracted from the data. For example, there is an unaccompoanied child standing at the edge of the road. The driver starts slowing down in response. However, he wouldn’t do this if the child was with an adult. The signature for this is classified under “Unaccompanied child – below 2 years, at edge of class 2 suburban road, low light, no rain, weekend, low traffic, max speed 40 km/hr”. As more and more drivers encounter such situations, the signatures become relaible, and the speed profile data can be programmed into an AV, with data available for a wide variety of conditions.
Using such signatures will reduce or negate the need for these actions and reactions of the driver to be manually programmed into AV software by a human programmer. Such signatures carry a wealth of human knowledge, experience and logic accumulated over years and spread among a wide variety of geographies and populations, and their trade-offs with rationalization and risk management, allowing safe, fast, efficient and pleasant transportation.
As societies transition towards non-human vehicle operators, all this is saved as signatures for use by AVs without being lost to time.
Problem: Identifying good drivers
We don’t want to base AV training data off bad drivers.
The solution?
Perception and Actuation Data is collected automatically from a large group of drivers while they drive their own cars during their routine lives.
Outside events are automatically identified from this data, and event signatures automatically extracted.
This data is then used to automatically score each driver, and from this group, expert drivers identified.
Is scoring that simple?
No, you have to be smart about what type of data is used. There are 2 driving modes:
(1) routine driving, when no outside events occur (called non-events).
(2) driving when outside events occur.
The trick is to score them separately, scale them, and then combine them.
What data do event signatures contain?
Signatures of events include data related to:
Event name, saccades and gaze positions of the eye and corresponding video frames of the road ahead, object identification, geolocation, time, event start and end times, event type and category, light and weather conditions, vehicle speed profile etc. Each signature lasts for a duration, and data for this time-frame is collected.
With the collection of a large number of similar signatures, an AV is trained to react similarly when a similar situation is encountered.
For example, if several good drivers become cautious when encountering children (unaccompanied by an adult) on the edges of roads, but not when children are indeed accompanied by adults, this behavior is captured from all these drivers as multiple instances of similar signatures. When an AV encounters a similar situation, it performs a similar cautious routine, but not when children are accompanied by adults. Its the old school “monkey see, monkey do”, without requiring human programming. Such signatures will have multutudes of variations in them, collected by thousands of drivers under different conditions and different countries, with AVs able to react diffrently to each variation.
so, Camera or Lidar?
Perception in this model is technology agnostic- vision and lidar can be combined if necessary, or they can be used individually.
The reason for this is simple: we don’t need all information from the road ahead, we need only pertinent information. There is no point in being hyper-alert to every object on the road – it will slow down computation and therefore travel. The question that then arises is: what is pertinent information, and who makes that determination? Well, we should just leave this to a crowdsourced group of expert drivers. And extract data from their perception and responses.
The driver’s eyes saccade between objects on the road ahead, forming fixations, dwells and regions of interest around pertinent objects. These eye movements can be one-to-one mapped to images obtained from any one or a combination of cameras, lidars and radars depending on what works best under the current environmental condition.
Capturing Visual Perception
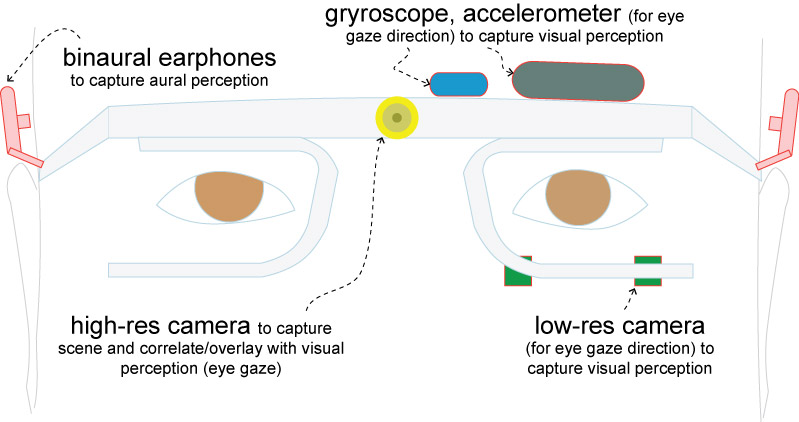
Human eyes move constantly. When driving, eyes scan the scene ahead by moving (called saccades) from object to object, fix their gaze on some objects (called fixations), dwell on some areas and form regions of interest. Eye trackers are used to record what the eyes perceive. Eye tracking can be done using smartphone apps as well as standalone cameras. For better data acquisition when eye movements are accompanied by head movements, a head mounted frame can be used.
Figure below shows a typical frame to track eye movement. It includes one or two cameras eye tracking cameras, a high-res scene camera to catpure the road ahead, a gyro and accelrometer to track head movement.
Example of Visual Perception
As an example, the figure below shows a woman walking a large dog and about to enter a road. After noticing this in his peripheral vision, the driver’s eyes saccade from the road ahead to the dog, and then to the woman, fixating on different portions and saccading around the woman and the dog, forming regions of interest around them.
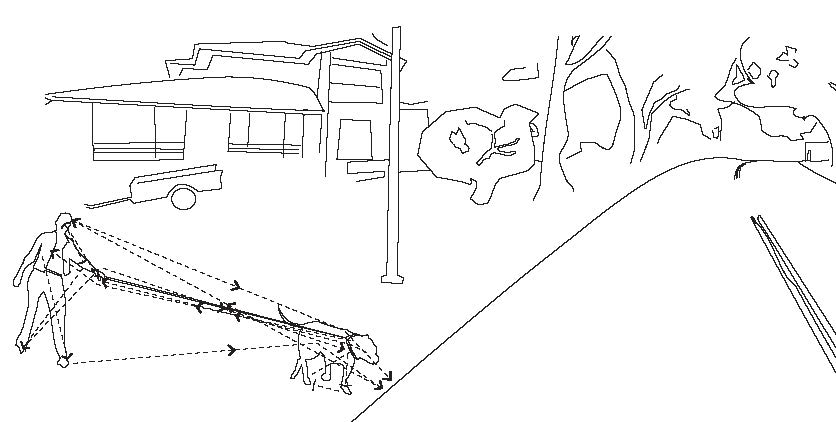
The eye movements for an interval of a few seconds is reproduced below, and includes fixation durations. Saccades are indicated by lines with arrows, fixations by circles (circle size indicating duration).
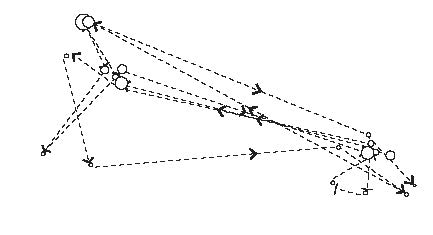
The above data is superimposed on the scene captured by a camera or lidar, and features extracted from regions of interest that are automatically detected. As can be seen in the figure above, there are two ROIs). Features are then identified as being a large dog, a woman, and a stretched leash. An expert driver will invariably recognize this situation as the dog dragging the woman into the road, and therefore a possible collision with the vehicle. The driver will therefore slow the vehicle down, the speed profile depending on the speed limit and width of the road, speed of the dog, how much the woman leans, weight of the vehicle etc.
Compare this with the same dog not tugging on the leash as shown below.
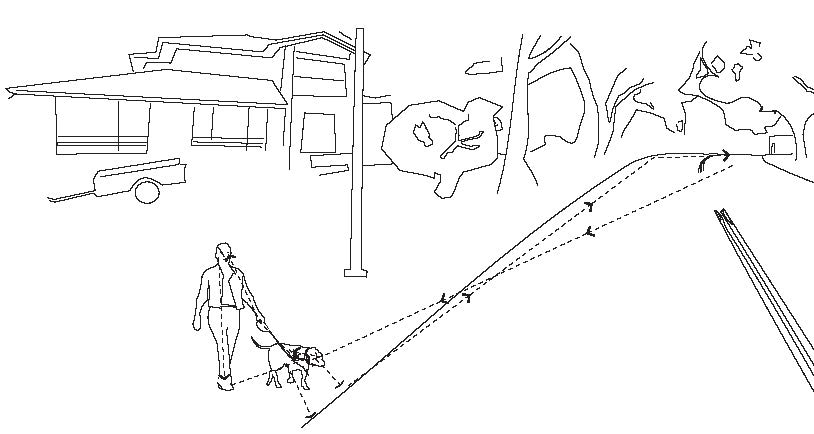
The driver, recognising a smaller probability of an accident, will slow the vehicle down at a much different speed profile than if the dog were tugging on the leash. Although both situations are captured under the same subheading of large-dog-with-adult-female, they will be further sub-classified under taut-leash and slack-leash. All this data is automatically captured, signatures automatically extracted and ready to feed into an AV.
Capturing Aural Perception
In the figure of the eye tracker frame shown above, two aural devices can be seen. These are used as binaural earphones. Their placement on either sides of the head better match what the driver hears than if using a dashboard miunted microphone.
Hearing in humans does not work like microphones. The head snf nose casts a shadow of the sound, and is shaped by the geometry and material of the outer and middle ear. Some of the sound is transmitted through the head. This is mimicked by the frame arrangement (shown above) worn by the driver.
When deployed in an AV to capture sounds just like what a human woulr perceive, a truncated mannequin head is attached to the ceiling of the car (see below).
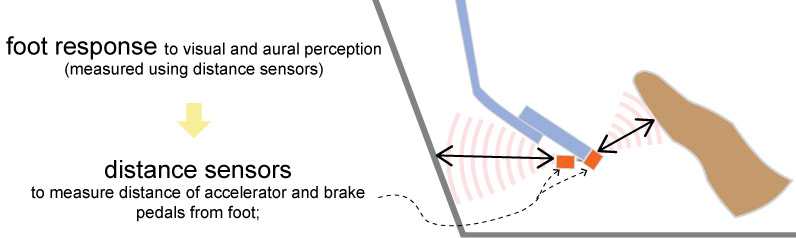
Foot actuation in response to visual and aural perception
The figure below shows sensors placed on the accelrator and brake pedals. These sensors provide the distance betwwn the foot and these pedals.
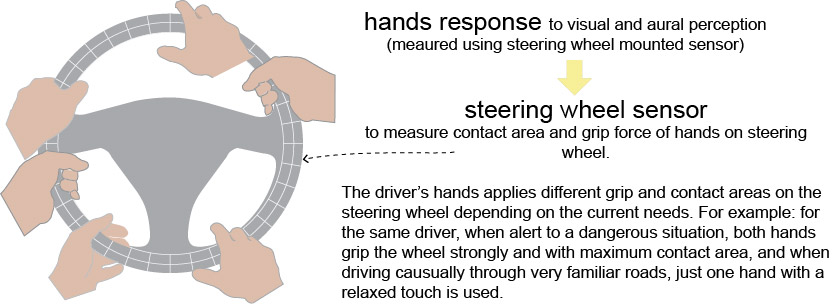
Hands actuation in response to visual and aural perception
The figure below shows sensors placed on the steering wheel. These sensors provide the grip force and contact area of the hands on the steering wheel.
Example of Foot and Hands actuation in response to Visual Perception
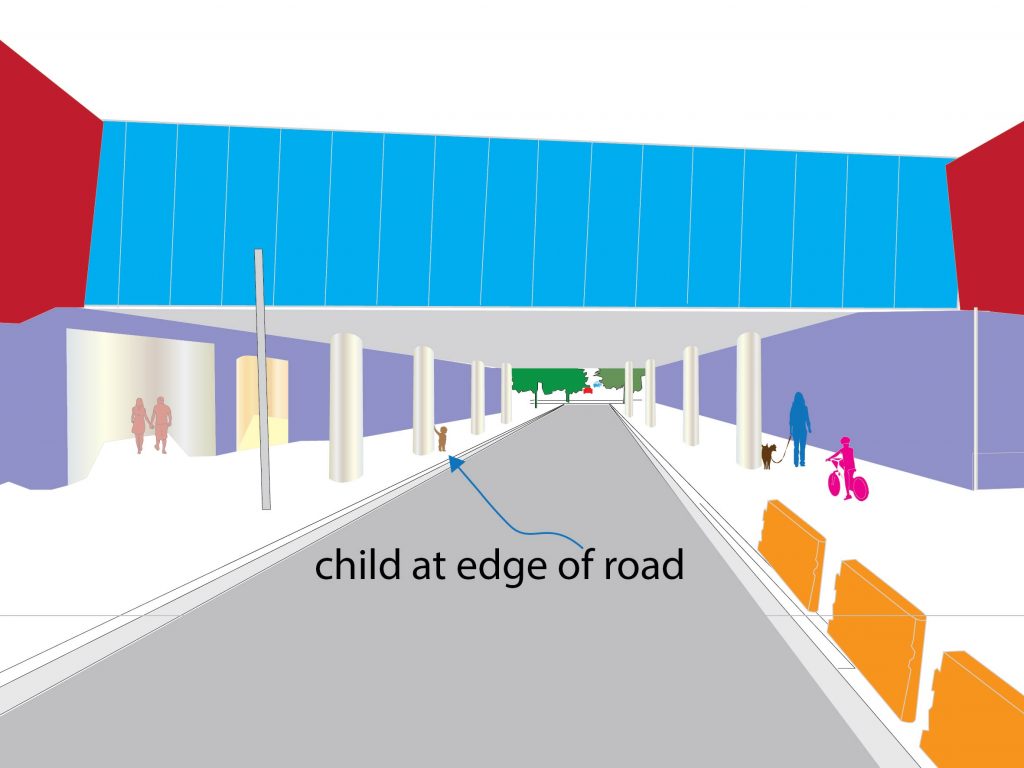
The figure below shows a scenario in which a small child is ambling towards the edge of the road. A car is going down the road at 36 km/hour. The driver sees the child 100 meters ahead emerging from behind a pillar, without an accompanying adult being visible.
An adult is holding the hand of the child, but hidden behind the pillar. The driver’s eyes saccade to the child and form an ROI, which includes checking for adults minding the child, and tracking the child moving closer to the road, interspersed with saccades to the road ahead. The driver has now become alert, and increased hand grip and contact area on the steering wheel. The foot goes off the accelerator and over the brake pedal.
With the eyes unable to find an accompanying adult, and the child being about 70 meters ahead, brakes are applied to lower the speed from the initial 36 km/hour to 18 km/hour in a span of 2 seconds. As the eyes saccade to and fro between the ROI-child (which is now about 60 meters ahead of the driver) and the road ahead, the child inches closer to the road. The driver is still unable to spot an adult. The car is slowed from 18 km/hour to 10 km/hour in 4 seconds.
The child is now 1.5 meters from the edge of the road, and the car is about 50 meters from the child. The brake pedal is kept depressed in preparation for a complete stop to take place about 10 meters from the child. However, 30 meters from the child, the driver is able to see the adult holding the child’s hand. The driver’s eyes saccade to the adult, fixate, and then establish an ROI around the adult plus child. The adult (who has apparently seen the approaching car) restrains the child from moving forward. The foot goes off the brake now. The driver then presses on the accelerator pedal to quickly bring back the speed to 36 km/hour.
This signature is captured and processed, and then filed under an “unaccompanied child approaching road” sub-category under main category “Child”. From the foregoing, it can be seen that the driver was being over-cautious. He reduced the speed to 5 km/hr at 50 meters from the child, even though the child was 1.5 meters from the road. However, when data is gathered from a large population of drivers, the average speed at 50 meters from the child would be 20 km/hr, which can be used by an actual AV.
insert EPO and ESCAF sample data here
Implementing visual and aural perception in AVs
After AVs have been trained with data acquired from expert drivers, it would ideal if the visual and aural perception is implemented to at least partially match the designs used during data acquisition. A trunacated mannequin is used for this purpose as shown below.
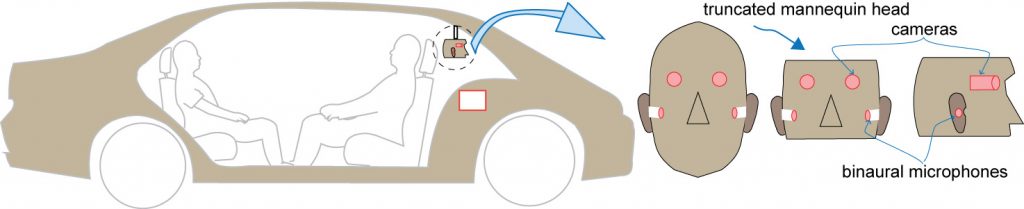
Although made mostly of polymer, the mannequn head’s density and sound conduction properties are similar to a human head, including the piinae (outer ear).
Drawbacks of current AV training practices
(Tesla not included)
Highly limiting fators include:
- Need HD maps,
- limited to geofenced areas,
- limited to rational, organized and strictly-legal driving conditions
- Ignores China and India: 35% of world population, 400% bigger than the GDP of USA in 10 years: huge market. However, difficult to gather data to train AVs in such regions through traditional means.
- Need to employ test drivers.
- Need expensive specially equipped cars in large numbers.
- Liability issues surrounding company cars and employed test drivers.
- Cannot quickly scale to millions of drivers.
- Cannot gather data from a wide variety of vehciels under wide variety of coinditions.
Will not allow for enough data gathering, is very expensive because the need for using company owned vehicles, paid drivers, and customized vehicles, the need to manually sort and program perception objects.
(Tesla is, to a large extent, lane detection and obstacle avoidance, with manual event detection and programming using accident or disengagement data)
Overcoming drawbacks
Instead, crowdsource: thousands of volunteer drivers spread around different countries driving their own cars during their routine lives.
Low capital requirement: Costs for AV companies limited to: software and data (smartphone app, computration, data warehousing), testing hardware of $200 sensor kit, no liabilities, millions of miles monthly from a wide variety of vehicles and conditions. No need to create HD maps, not limited to geofenced areas, available to users in all chosen countries, inlcuding China and India, quickly scale up as the program becomes popular.
Traffic rules are not followed always, chaotic, but there is a method to this madness. Millions of human drivers travel through these roads. We need to mimic the good drivers amongst these.
We should start thinking in terms of events rather than objects. Events account for contextualized objects within a time interval. Objects have different connotations under different contexts.
Event detection & signature acquisition is important, not just object recognition
We should start thinking in terms of events rather than objects. Events account for contextualized objects within a time interval. Objects have different connotations under different contexts.
Check out this scenario of figure 17
Defensive Driving
Its not going to be 100% switch to AVs on a particular day. Traffic is going to be mixed with AVs and non-AVs and things in between. So, have to drive defensively. Don’t expect drivers or pedestrians to be rational, be prepared for unexpected situations. Having 100% AVs on the roads is very different from humans mingled with AVs.
Good drivers drive defensively; how do we train AVs to drive defensively? Simnple, copy what expert drivers do.
How is AV training currently being done?
AVs are trained to follow road rules. These rules are known to all of us, and we know all of these rules have been made available to the public, nothing being secret, incomprehensible or unexpected. That is, we know all of these known rules. These are known knowns (KK).
AVs are also programmed to stop if a human or any obstruction appears in front of car, or to slow down if a vehicle is coming head-on in the same lane. These are known dangerous situations, that is, situations we are sure about, and are also therefore know knowns (KK).
There are numerous such known knowns (KK) that have already been programmed into AVs, including those that control test vehicles. When unknown or unexpected situations arise, disengagement occurs. The human test driver then takes over the AV to address this situation unknown to the AV. The data gathered from such disengagements is then used as a basis to further refine the AV software. That is, this unknown has been converted into a known.
Knowledge is based on many things you are not aware of — instincts, intuitions or other factors you think are trivial. Driving has become second nature to you, so you don’t realize all these things exist: these are unknown know
So, the next question would be: was this unknown situation something that we could have predicted would happen? That is, we never had the need or opportunity to program it into the AV until we encountered it in real life? And only after we encountered it did we realize that this situation was previously known to us, but had forgotten all about it, and thanks to this disengagement, we have rediscovered it and are programming the AV to address it in the future. This is an unknown known (UK).
Or was it something that we knew was within the realms of possibilities of things that could go wrong, but we didn’t know this particular variation would occur? That is, this was a known unknown (KU).
Or was it something that took us completely by surprise, having not known about it in the past, neither having been in the realm of possibility in the past, until we encountered it. This is an unknown unknown (UU).
In summary, known knowns (KK) have already been programmed into AVs, the rest (KU, UK, UU) are being discovered during AV training. It will take billions of miles of training data around all kinds of roads, in all kinds of weather conditions, traffic conditions, different countries, cities, villages, suburbs, week days, weekends, school days, holidays etc to come anywhere close to the driving skill levels of an ordinary human driver. The best and quickest way to do this using a crowdsourced bunch of drivers.