
Example of Visual Perception
The figure below shows a woman walking a large dog. After noticing this in his peripheral vision, the driver’s eyes saccade from the road ahead to the dog, and then to the woman, fixating on different portions and saccading around the woman and the dog, forming regions of interest around them.
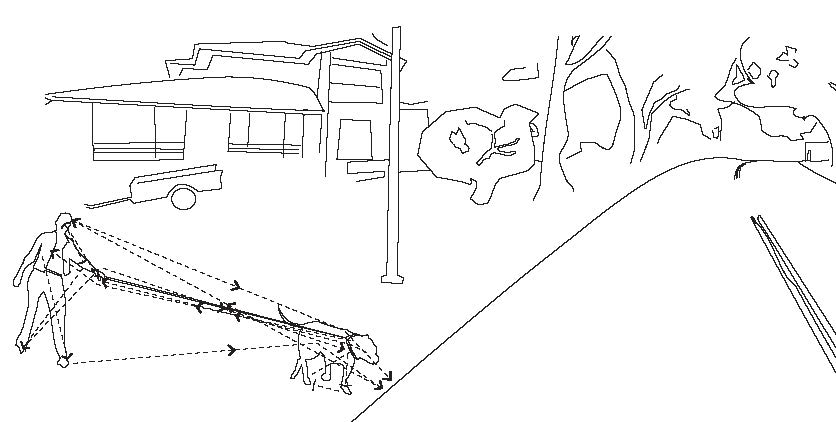
The eye movements for an interval of a few seconds is reproduced below, and includes fixation durations. Saccades are indicated by lines with arrows, fixations by circles (circle size indicating duration).
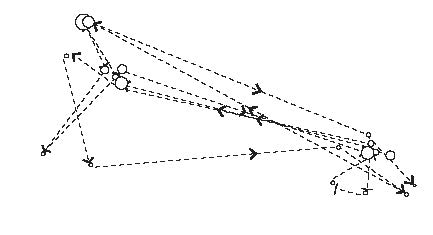
The above data is superimposed on the scene captured by a camera or lidar, and features extracted from regions of interest are automatically detected. As can be seen in the figure above, there are two ROIs. Features are then identified as being a large dog, a woman, and a stretched leash. An expert driver will invariably recognize the dog dragging the woman into the road, and therefore a possible collision. The driver will slow the vehicle down, the speed profile depending on the speed limit and width of the road, strength of the dog, how much the woman leans, weight of the vehicle etc.
Compare this with the same dog not tugging on the leash as shown below.
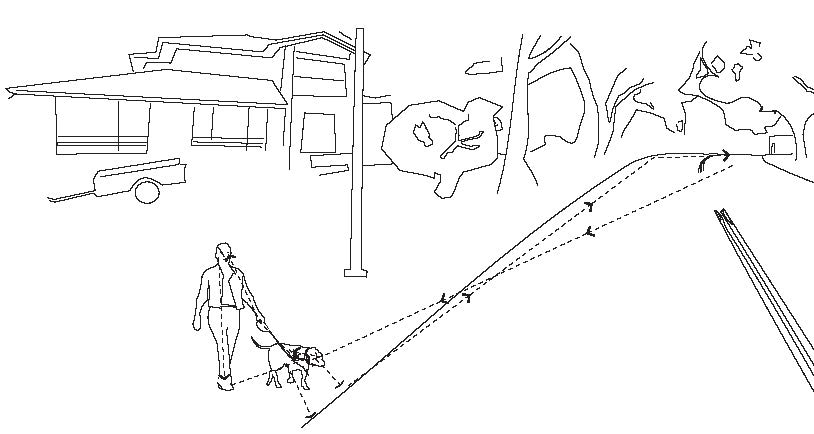
The driver, recognizing a smaller probability of an accident, will slow the vehicle down at a much different speed profile than if the dog were tugging at the leash. Although both situations are captured under the same subheading of “large-dog-with-adult-female”, they will be further sub-classified under “taut-leash” or “slack-leash”. All this data is automatically captured, signatures automatically extracted and ready to feed into an AV.